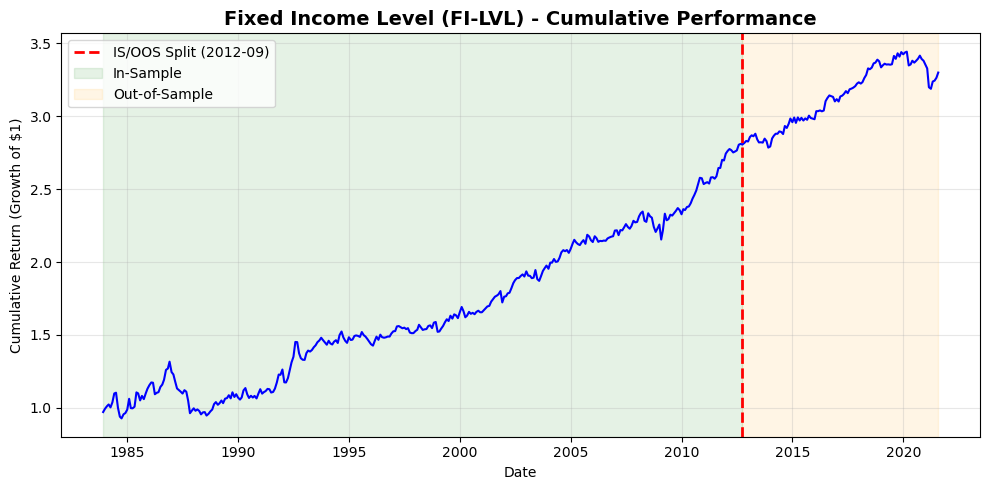
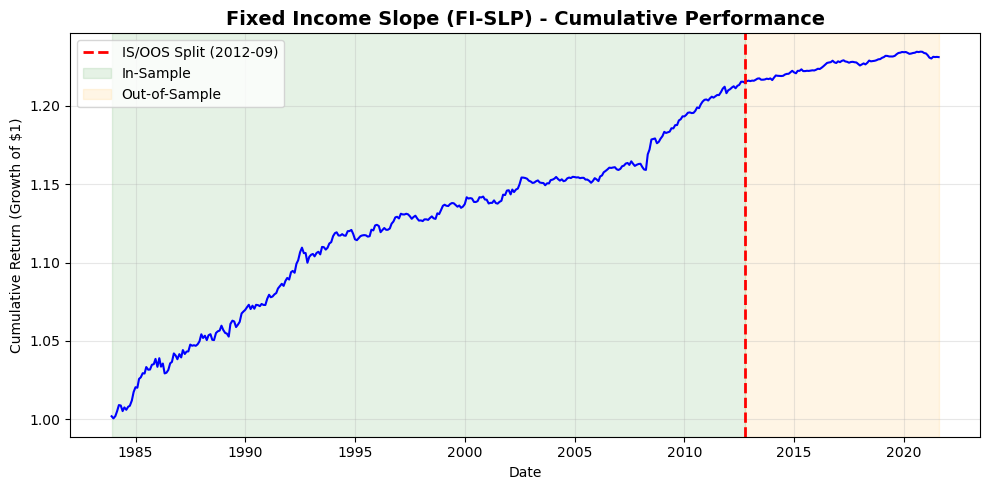
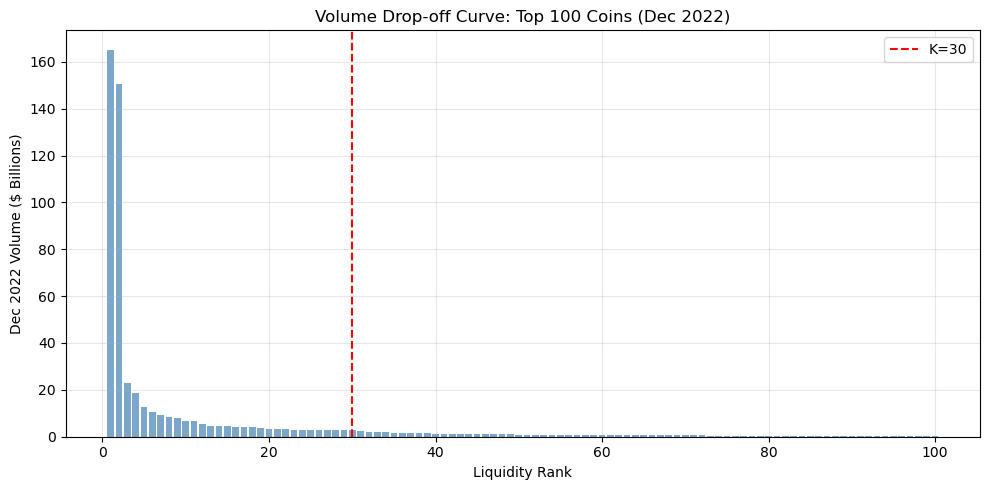
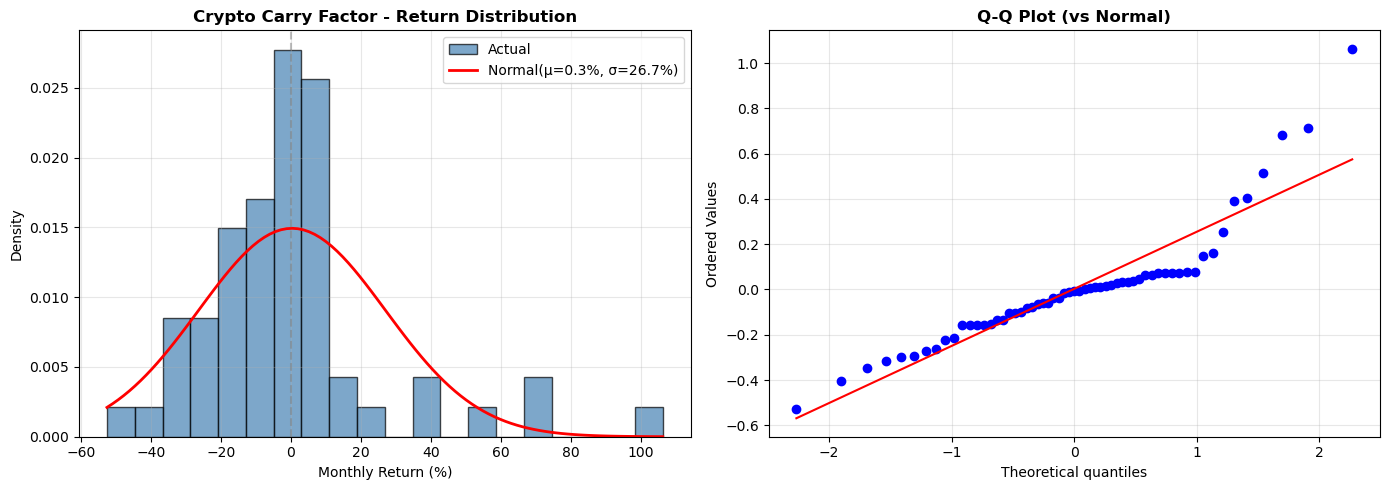
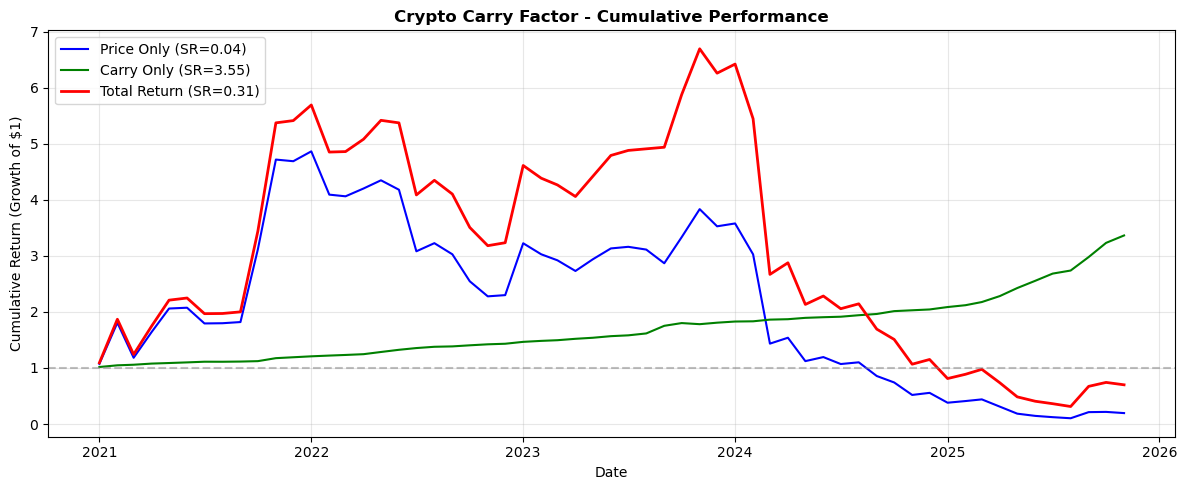
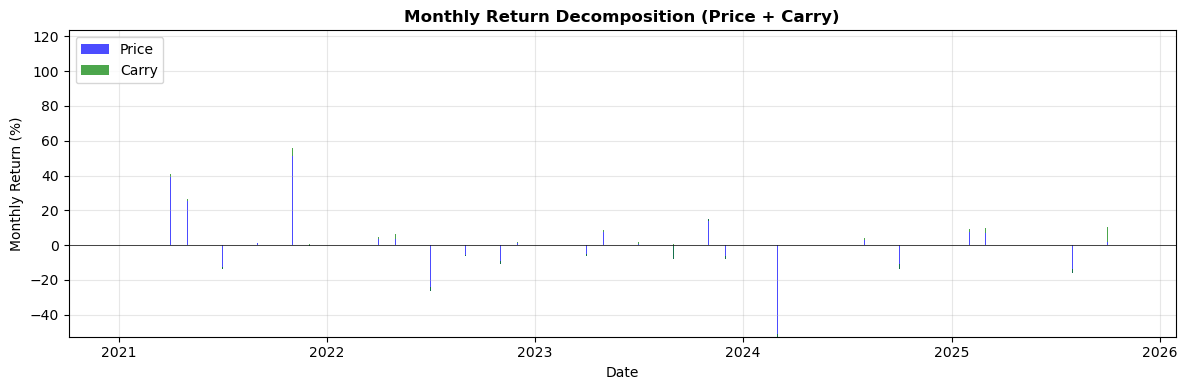
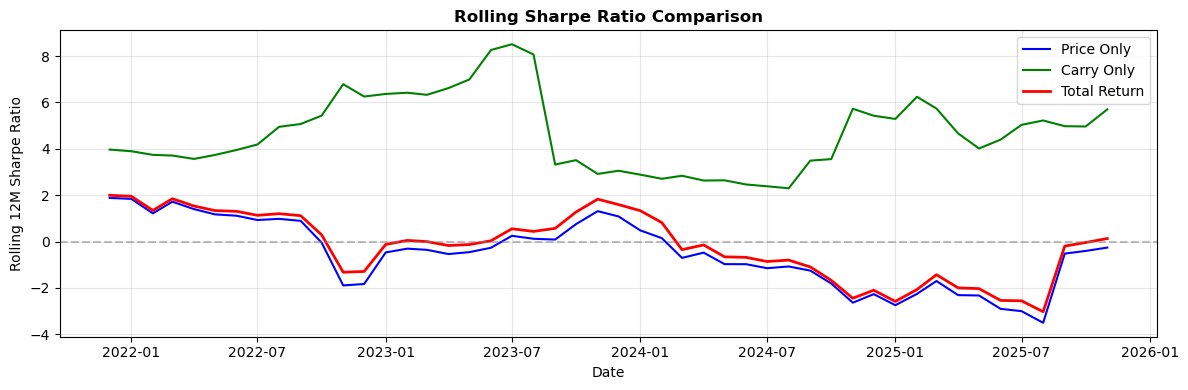
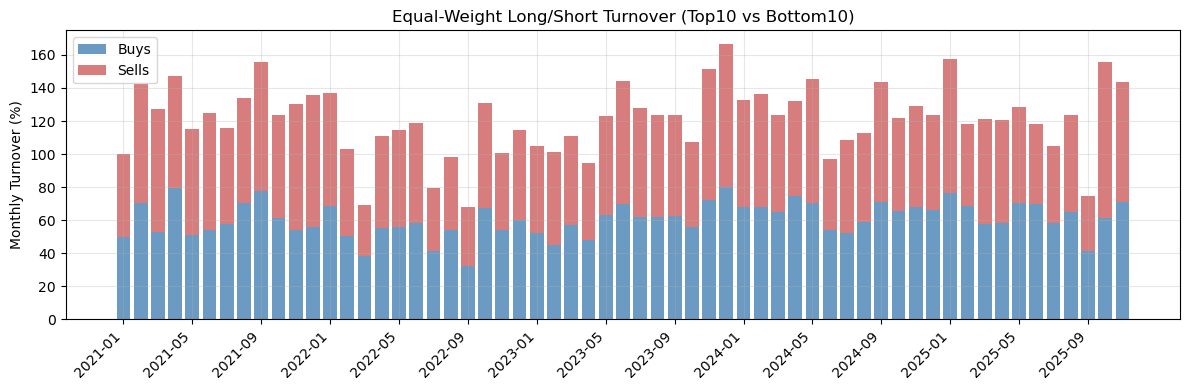
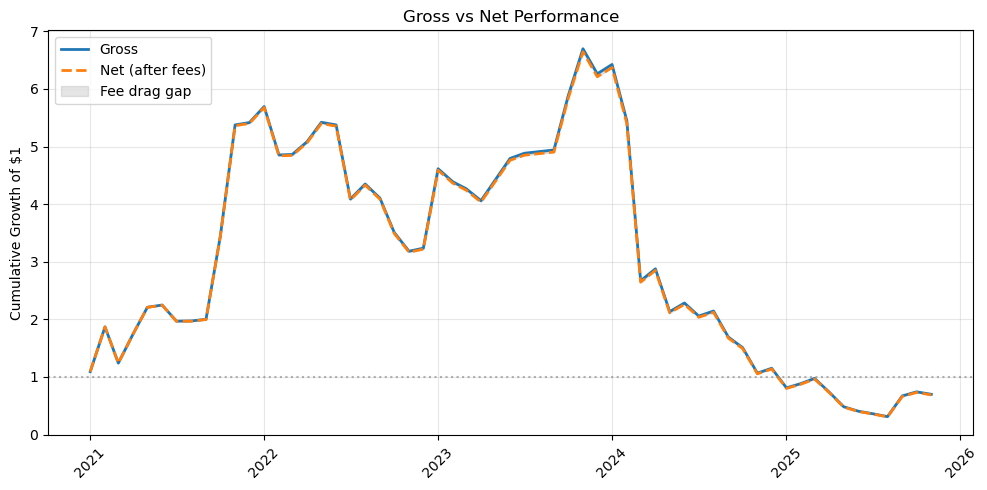
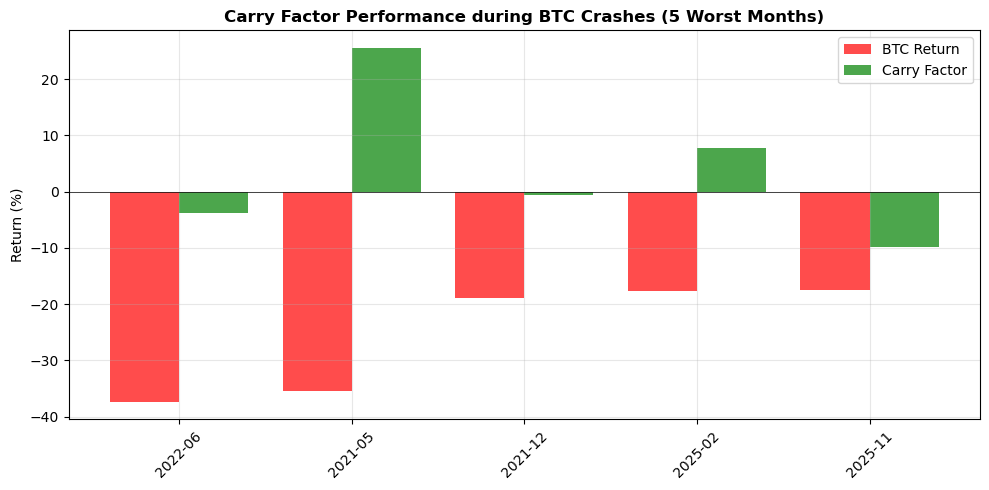
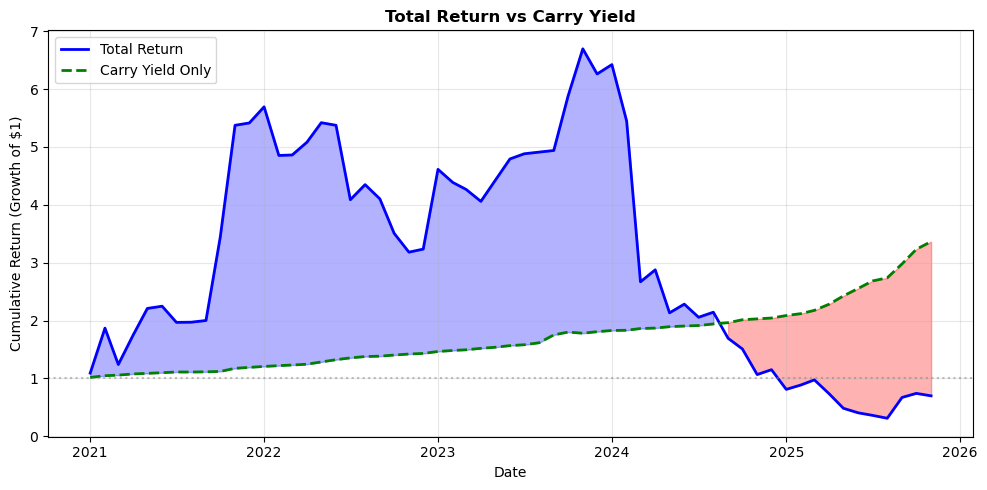
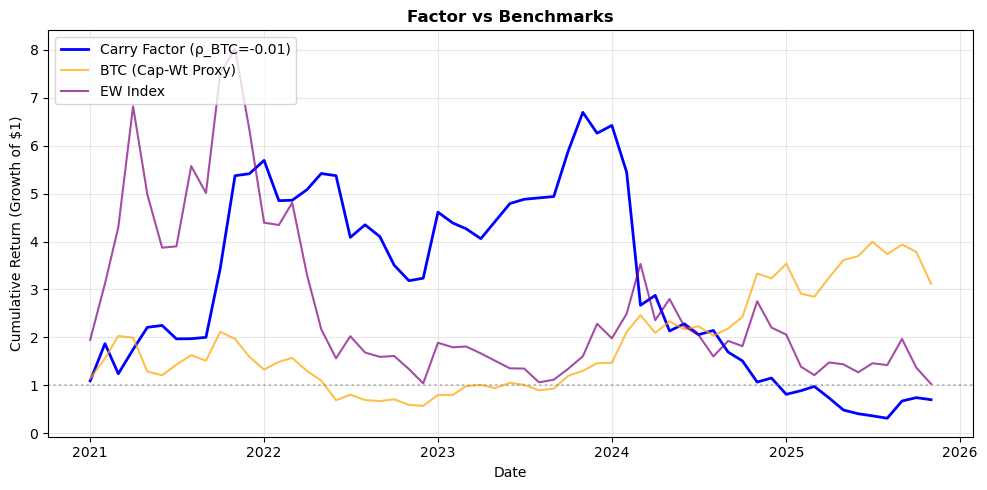
# Fetching full dataset
import os
import requests
import pandas as pd
import numpy as np
from datetime import datetime
from dateutil.relativedelta import relativedelta
from tqdm import tqdm
import time
PANEL_FILE = "data/crypto_factor/crypto_panel.csv"
FACTOR_FILE = "data/crypto_factor/crypto_factor.csv"
# Skip if data already exists
if os.path.exists(PANEL_FILE) and os.path.exists(FACTOR_FILE):
print(f"Data already exists: {PANEL_FILE}")
print("Skipping fetch. Delete files to re-fetch.")
else:
os.makedirs("data/crypto_factor", exist_ok=True)
BASE_URL = "https://fapi.binance.com"
START_DATE = datetime(2021, 1, 1)
END_DATE = datetime(2025, 11, 1)
TOP_K = 30
API_DELAY = 0.15
rebal_dates = []
current = START_DATE
while current <= END_DATE:
rebal_dates.append(current)
current += relativedelta(months=1)
print(f"Backtest period: {START_DATE.strftime('%Y-%m')} to {END_DATE.strftime('%Y-%m')}")
print(f"Total months: {len(rebal_dates)}, Universe: Top {TOP_K}")
def get_all_usdt_perpetuals():
resp = requests.get(f"{BASE_URL}/fapi/v1/exchangeInfo")
resp.raise_for_status()
return [s['symbol'] for s in resp.json()['symbols']
if s['symbol'].endswith('USDT') and s['contractType'] == 'PERPETUAL']
def get_monthly_volume(symbol, start_ts, end_ts):
try:
resp = requests.get(f"{BASE_URL}/fapi/v1/klines", params={
"symbol": symbol, "interval": "1M", "startTime": start_ts, "endTime": end_ts, "limit": 1})
data = resp.json()
return float(data[0][7]) if data else None
except: return None
def get_monthly_funding(symbol, start_ts, end_ts):
try:
resp = requests.get(f"{BASE_URL}/fapi/v1/fundingRate", params={
"symbol": symbol, "startTime": start_ts, "endTime": end_ts, "limit": 1000})
data = resp.json()
return np.mean([float(r['fundingRate']) for r in data]) if data else None
except: return None
def get_monthly_return(symbol, start_ts, end_ts):
try:
resp = requests.get(f"{BASE_URL}/fapi/v1/klines", params={
"symbol": symbol, "interval": "1M", "startTime": start_ts, "endTime": end_ts, "limit": 1})
data = resp.json()
if data:
open_p, close_p = float(data[0][1]), float(data[0][4])
return (close_p - open_p) / open_p if open_p > 0 else None
except: pass
return None
def month_to_ts(dt):
return int(dt.timestamp() * 1000)
def get_month_range(dt):
start = datetime(dt.year, dt.month, 1)
end = start + relativedelta(months=1) - relativedelta(seconds=1)
return month_to_ts(start), month_to_ts(end)
def compute_factor_return(month_panel):
if len(month_panel) < 20:
return None
sorted_df = month_panel.sort_values('carry_signal', ascending=False)
long_ret = sorted_df.head(10)['ret_1m'].mean()
short_ret = sorted_df.tail(10)['ret_1m'].mean()
return {'date': month_panel['date'].iloc[0], 'long_ret': long_ret,
'short_ret': short_ret, 'factor_ret': long_ret - short_ret, 'n_assets': len(month_panel)}
# Check existing progress
completed_dates = set()
if os.path.exists(PANEL_FILE):
existing = pd.read_csv(PANEL_FILE, parse_dates=['date'])
completed_dates = set(existing['date'].dt.strftime('%Y-%m-%d'))
print(f"Resuming: {len(completed_dates)} months done")
remaining = [d for d in rebal_dates if d.strftime('%Y-%m-%d') not in completed_dates]
print(f"Remaining: {len(remaining)} months")
if remaining:
all_symbols = get_all_usdt_perpetuals()
print(f"USDT perpetuals: {len(all_symbols)}")
for i, rebal_date in enumerate(remaining):
date_str = rebal_date.strftime('%Y-%m-%d')
print(f"\nProcessing {date_str} ({i+1}/{len(remaining)})")
prior_month = rebal_date - relativedelta(months=1)
prior_start, prior_end = get_month_range(prior_month)
volumes = {}
for sym in tqdm(all_symbols, desc="Volume", leave=False):
vol = get_monthly_volume(sym, prior_start, prior_end)
if vol and vol > 0: volumes[sym] = vol
time.sleep(API_DELAY * 0.3)
universe = sorted(volumes.keys(), key=lambda x: volumes[x], reverse=True)[:TOP_K]
curr_start, curr_end = get_month_range(rebal_date)
records = []
for sym in tqdm(universe, desc="Signals", leave=False):
avg_funding = get_monthly_funding(sym, prior_start, prior_end)
carry_signal = avg_funding * -1 * 3 * 365 if avg_funding else None
ret_1m = get_monthly_return(sym, curr_start, curr_end)
records.append({'date': date_str, 'symbol': sym, 'carry_signal': carry_signal, 'ret_1m': ret_1m})
time.sleep(API_DELAY)
month_panel = pd.DataFrame(records).dropna(subset=['carry_signal', 'ret_1m'])
month_panel.to_csv(PANEL_FILE, mode='a', header=not os.path.exists(PANEL_FILE), index=False)
factor_row = compute_factor_return(month_panel)
if factor_row:
pd.DataFrame([factor_row]).to_csv(FACTOR_FILE, mode='a', header=not os.path.exists(FACTOR_FILE), index=False)
print(f" ✓ {len(month_panel)} rows, factor_ret={factor_row['factor_ret']*100:.2f}%" if factor_row else " ✓ Saved")
print(f"\nComplete: {PANEL_FILE}, {FACTOR_FILE}")