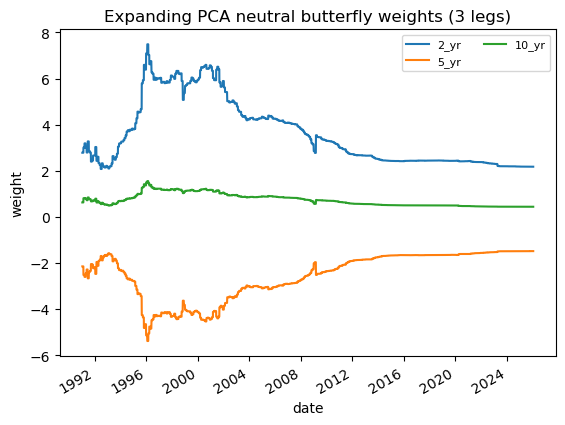
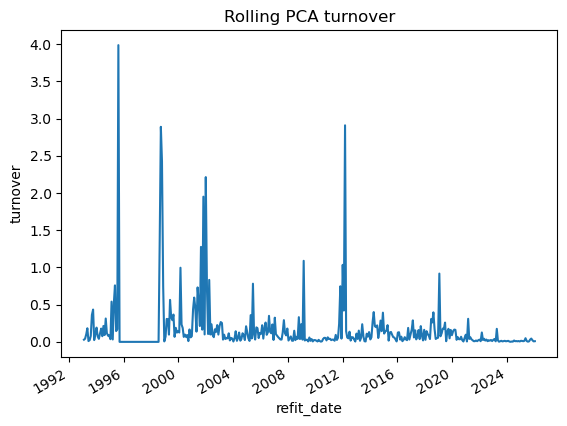
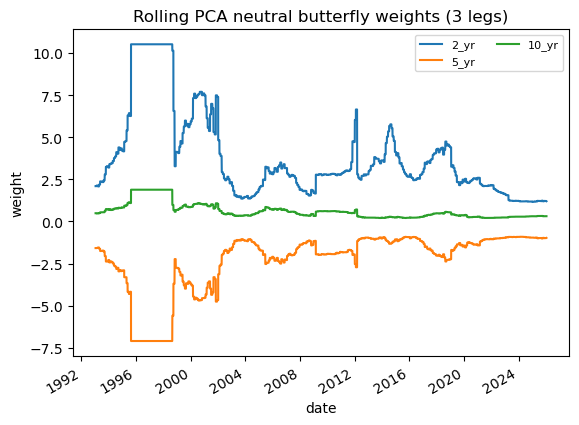
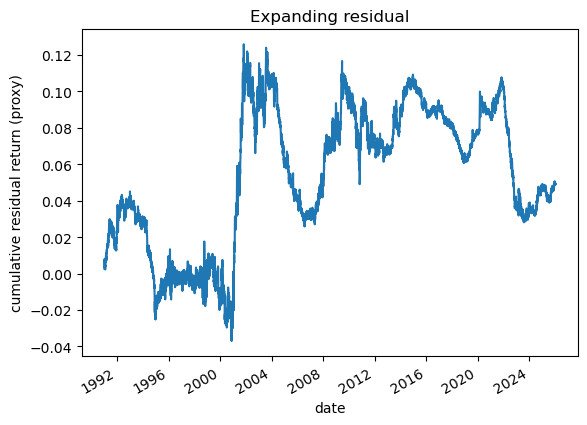
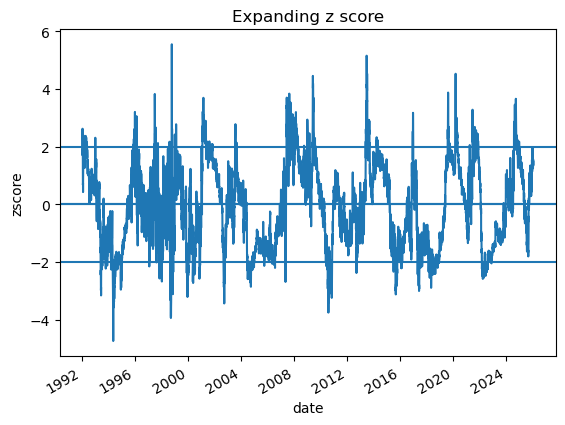
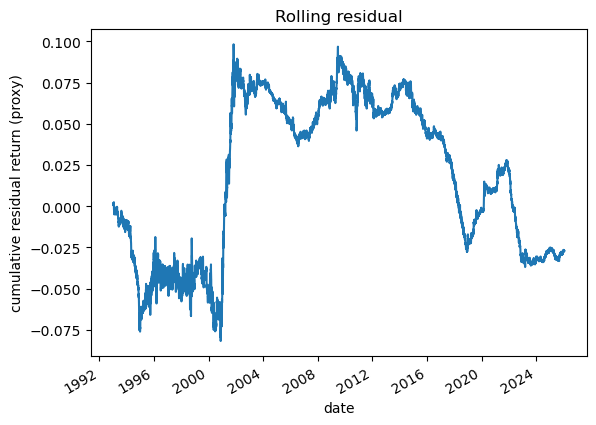
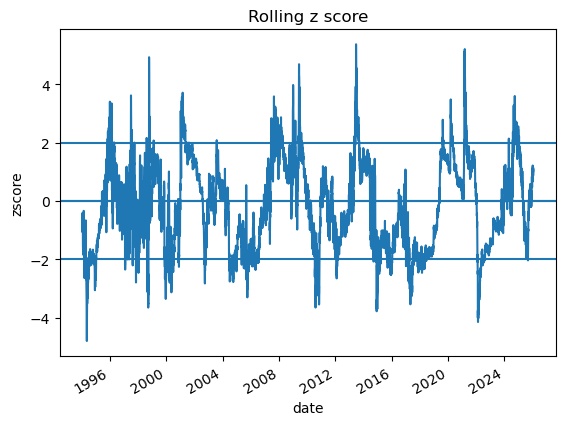
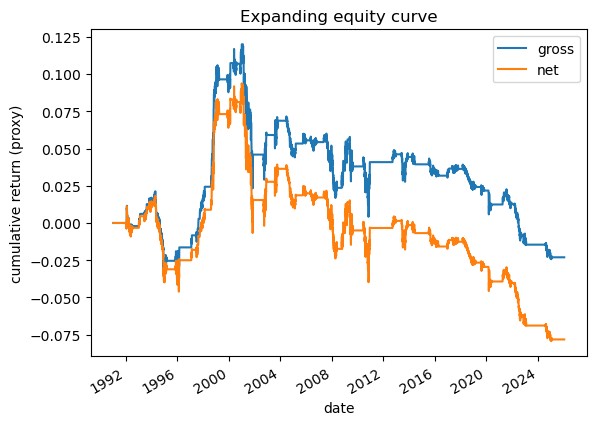
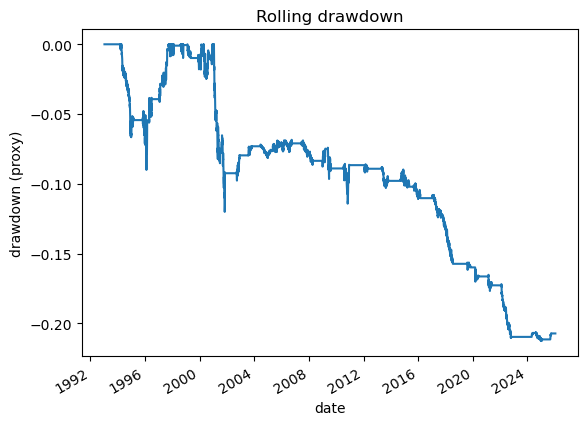
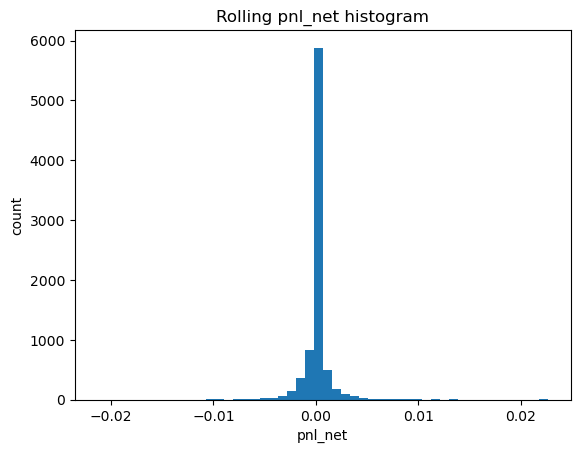
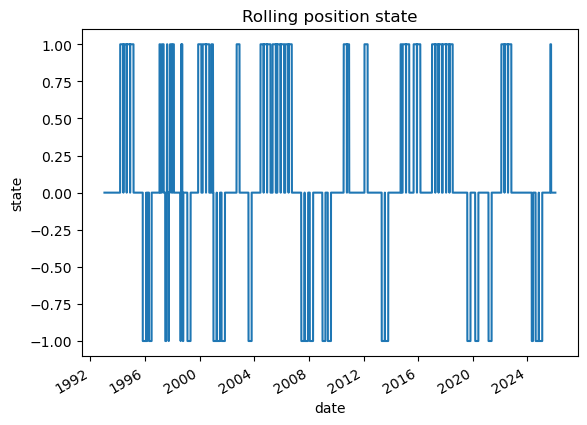
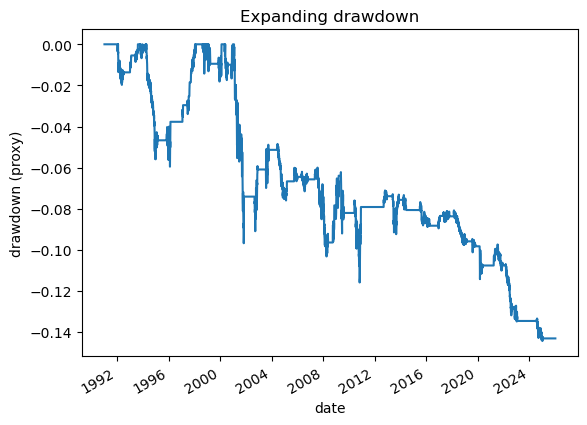
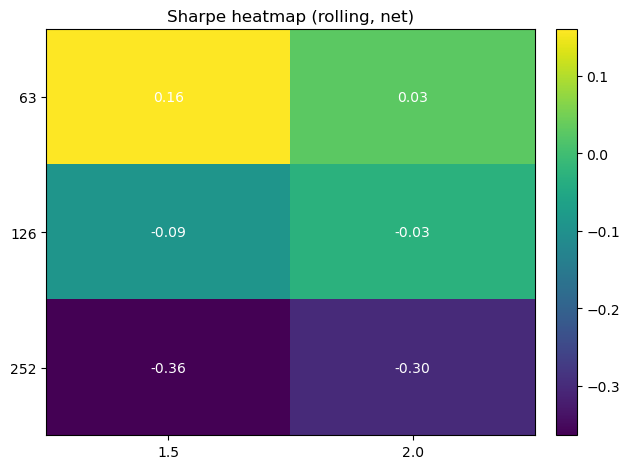
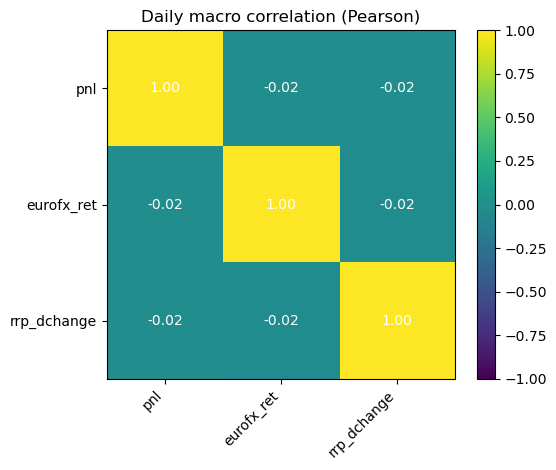
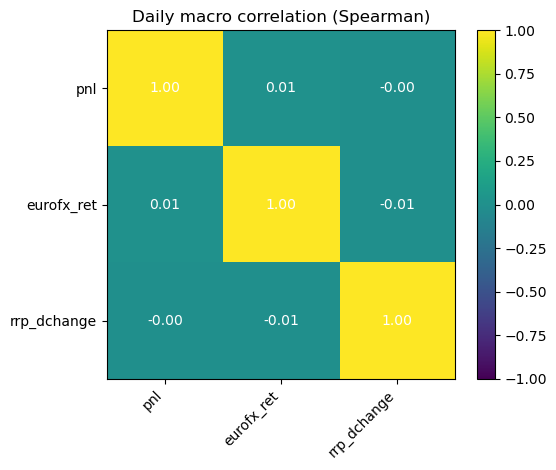
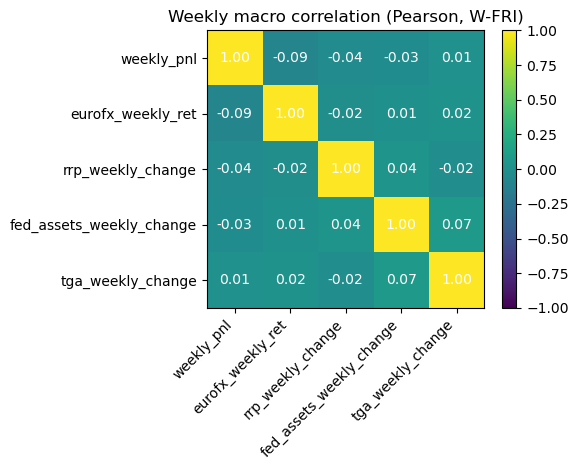
# 2.1 Imports and paths
from pathlib import Path
import itertools
import json
import os
import warnings
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.tsa.stattools import adfuller, kpss
from tabulate import tabulate
# Wide-format parquet holds all series aligned by date; this is a statistical data audit, not a tradeable panel.
input_path = "data/combined/all_datasets_wide.parquet"
out_dir = Path("data/derived")
out_dir.mkdir(parents=True, exist_ok=True)
def show_table(df_table: pd.DataFrame) -> None:
print(tabulate(df_table, headers="keys", tablefmt="psql", showindex=False))
def write_df_csv_and_md(
df: pd.DataFrame, csv_path: Path, md_path: Path, float_round: int = 6
) -> None:
df.to_csv(csv_path, index=False)
df_md = df.copy()
num_cols = df_md.select_dtypes(include=["number"]).columns
df_md[num_cols] = df_md[num_cols].round(float_round)
md_path.write_text(df_md.to_markdown(index=False), encoding="utf-8")
def ensure_naive_dates(index: pd.Index | pd.DatetimeIndex) -> pd.DatetimeIndex:
idx = pd.to_datetime(index, errors="coerce")
if getattr(idx, "tz", None) is not None:
# Drop timezone without shifting calendar dates.
idx = idx.tz_localize(None)
return idx
def compute_missing_streaks(series: pd.Series, index: pd.DatetimeIndex) -> pd.DataFrame:
is_missing = series.isna().astype(int).values
idx = index
segments = []
i = 0
n = len(is_missing)
while i < n:
if is_missing[i] == 1:
j = i + 1
while j < n and is_missing[j] == 1:
j += 1
start = idx[i]
end = idx[j - 1]
length_days = (end - start).days + 1
length_bus = int(j - i)
segments.append(
{
"segment_start": start,
"segment_end": end,
"length_days": length_days,
"length_business_days": length_bus,
}
)
i = j
else:
i += 1
return pd.DataFrame(segments)
def apply_causality_shift(
refit_wide: pd.DataFrame, trade_index: pd.DatetimeIndex, label: str
) -> tuple[pd.DataFrame, pd.Series]:
if refit_wide.index.has_duplicates:
raise ValueError(f"{label}: refit index has duplicates; cannot apply causality shift safely.")
trade_index = ensure_naive_dates(trade_index)
trade_index = trade_index.sort_values()
refit_wide = refit_wide.sort_index()
# Forward-fill refit outputs to daily, then shift 1 observation to enforce t-1 information.
daily = refit_wide.reindex(trade_index).ffill().shift(1)
refit_marker = pd.Series(refit_wide.index, index=refit_wide.index, name="refit_date")
refit_daily = refit_marker.reindex(trade_index).ffill().shift(1)
daily = daily.dropna(axis=0, how="any")
refit_daily = refit_daily.reindex(daily.index)
if len(daily) and not daily.index.is_monotonic_increasing:
raise ValueError(f"{label}: daily index not monotonic after shift.")
return daily, refit_daily
def is_treasury_par_curve_tenor(name: str) -> bool:
s = str(name).lower()
parts = s.split("_")
if len(parts) != 2:
return False
n, unit = parts
if not n.isdigit():
return False
return unit in {"mo", "yr", "month", "months"}
def tenor_to_years(tenor: str) -> float:
mapping = {
"3_mo": 0.25,
"6_mo": 0.50,
"1_yr": 1.00,
"2_yr": 2.00,
"3_yr": 3.00,
"5_yr": 5.00,
"7_yr": 7.00,
"10_yr": 10.00,
}
if tenor not in mapping:
raise ValueError(f"Unsupported tenor for duration mapping: {tenor!r}")
return float(mapping[tenor])
def modified_duration_from_yield(y_decimal: float, maturity_years: float) -> float:
if not np.isfinite(y_decimal):
return np.nan
if maturity_years < 1.0:
denom = 1.0 + y_decimal
return float(maturity_years / denom) if denom > 0 else np.nan
face = 100.0
if maturity_years == 1.0:
freq = 1
else:
freq = 2
per = y_decimal / freq
denom = 1.0 + per
if denom <= 0:
return np.nan
n_periods = int(round(maturity_years * freq))
if n_periods <= 0:
return np.nan
coupon = face * y_decimal / freq
price = 0.0
weighted_sum = 0.0
for i in range(1, n_periods + 1):
t_years = i / freq
cf = coupon + (face if i == n_periods else 0.0)
pv = cf / (denom ** i)
price += pv
weighted_sum += t_years * pv
if price <= 0:
return np.nan
macaulay = weighted_sum / price
modified = macaulay / denom
return float(modified)
def build_duration_panel(
df_yields_percent: pd.DataFrame, tenors: list[str]
) -> pd.DataFrame:
panel = pd.DataFrame(index=df_yields_percent.index, columns=tenors, dtype="float64")
for tenor in tenors:
maturity_years = tenor_to_years(tenor)
y_series = df_yields_percent[tenor].astype("float64")
panel[tenor] = y_series.apply(
lambda y: modified_duration_from_yield(y / 100.0, maturity_years)
if pd.notna(y)
else np.nan
)
return panel
def build_dv01_returns(
df_yields: pd.DataFrame, dur_input: pd.Series | pd.DataFrame
) -> tuple[pd.DataFrame, pd.DataFrame]:
# Output is a dimensionless first-order price return proxy from yield changes using a duration proxy in years.
# It is not a dollar DV01, not a bond total return, and not a tradeable instrument PnL.
dy_decimal = df_yields.diff().div(100.0)
if isinstance(dur_input, pd.Series):
dur_vec = dur_input.reindex(df_yields.columns)
missing = dur_vec[dur_vec.isna()].index.tolist()
if missing:
raise ValueError(f"Missing duration assumptions for tenors: {missing}")
duration_scaled_return_proxy = dy_decimal.mul(-dur_vec, axis=1)
else:
dur_panel = dur_input.reindex(index=df_yields.index, columns=df_yields.columns)
dur_panel = dur_panel.shift(1)
duration_scaled_return_proxy = dy_decimal * (-dur_panel)
dy_decimal = dy_decimal.dropna(axis=0, how="any")
duration_scaled_return_proxy = (
duration_scaled_return_proxy.reindex(dy_decimal.index).dropna(axis=0, how="any")
)
dy_decimal = dy_decimal.reindex(duration_scaled_return_proxy.index)
return dy_decimal, duration_scaled_return_proxy
# Units note for the duration scaled return proxy
# If duration is 5 years and yield rises by 1 bp then dy_decimal is 0.0001 and the proxy return is about -0.0005,
# which is about -5 bp in price return terms.
def pca_svd(Xc: np.ndarray, k: int = 3) -> tuple[np.ndarray, np.ndarray, np.ndarray]:
if Xc.ndim != 2:
raise ValueError("Xc must be 2D array")
n_obs = Xc.shape[0]
if n_obs < 2:
raise ValueError("Need at least 2 observations for PCA")
U, S, Vt = np.linalg.svd(Xc, full_matrices=False)
loadings = Vt[:k, :]
scores = U[:, :k] * S[:k]
var = (S**2) / max(n_obs - 1, 1)
evr = var[:k] / var.sum()
return loadings, scores, evr
def align_signs(loadings: np.ndarray, tenors: list[str]) -> np.ndarray:
aligned = loadings.copy()
tenor_index = {t: i for i, t in enumerate(tenors)}
if np.nanmean(aligned[0]) < 0:
aligned[0] *= -1
idx_3m = tenor_index.get("3_mo")
idx_10y = tenor_index.get("10_yr")
idx_5y = tenor_index.get("5_yr")
if idx_3m is not None and idx_10y is not None:
slope = aligned[1, idx_10y] - aligned[1, idx_3m]
if slope < 0:
aligned[1] *= -1
if idx_3m is not None and idx_10y is not None and idx_5y is not None:
wings = 0.5 * (aligned[2, idx_3m] + aligned[2, idx_10y])
belly = aligned[2, idx_5y]
if (wings - belly) < 0:
aligned[2] *= -1
return aligned
def _match_and_orient_impl(
loadings_now: np.ndarray, loadings_prev: np.ndarray | None
) -> tuple[np.ndarray, str, list[bool], list[float]]:
if loadings_now.ndim != 2:
raise ValueError("loadings_now must be a 2D array")
if loadings_prev is None:
k = loadings_now.shape[0]
sims = [np.nan] * k
flip_flags = [False] * k
perm_used = "-".join(str(i) for i in range(k))
return loadings_now.copy(), perm_used, flip_flags, sims
if loadings_prev.ndim != 2:
raise ValueError("loadings_prev must be a 2D array")
if loadings_prev.shape != loadings_now.shape:
raise ValueError(
"loadings_prev and loadings_now must have matching shapes; "
f"got {loadings_prev.shape} and {loadings_now.shape}"
)
k = loadings_now.shape[0]
if k == 0:
return loadings_now.copy(), "", [], []
perms = list(itertools.permutations(range(k)))
best_perm = perms[0]
best_score = -np.inf
for perm in perms:
score = 0.0
for i in range(k):
score += abs(float(np.dot(loadings_now[perm[i]], loadings_prev[i])))
if score > best_score:
best_score = score
best_perm = perm
aligned = loadings_now[list(best_perm), :].copy()
flip_flags: list[bool] = []
sims: list[float] = []
for i in range(k):
dot_val = float(np.dot(aligned[i], loadings_prev[i]))
if dot_val < 0:
aligned[i] *= -1
flip_flags.append(True)
dot_val = -dot_val
else:
flip_flags.append(False)
sims.append(dot_val)
perm_used = "-".join(str(i) for i in best_perm)
return aligned, perm_used, flip_flags, sims
def _parse_perm_used(perm_used: str, k: int) -> list[int]:
if k == 0:
return []
if not perm_used:
return list(range(k))
parts = perm_used.split("-")
if len(parts) != k:
raise ValueError(f"perm_used has length {len(parts)} but expected {k}")
perm = [int(p) for p in parts]
if sorted(perm) != list(range(k)):
raise ValueError(f"perm_used is not a valid permutation: {perm_used}")
return perm
def _apply_component_alignment(
arr: np.ndarray, perm: list[int], flip_flags: list[bool] | None = None
) -> np.ndarray:
aligned = np.asarray(arr)[perm].copy()
if flip_flags:
signs = np.where(np.array(flip_flags, dtype=bool), -1.0, 1.0)
aligned *= signs.reshape((len(signs),) + (1,) * (aligned.ndim - 1))
return aligned
def _self_test_match_and_orient_impl() -> None:
rng = np.random.default_rng(0)
k, n = 3, 7
A = rng.normal(size=(k, n))
q, _ = np.linalg.qr(A.T)
loadings_prev = q.T
perm = np.array([2, 0, 1])
signs = rng.choice([-1.0, 1.0], size=k)
loadings_now = signs[:, None] * loadings_prev[perm]
aligned, _, _, _ = _match_and_orient_impl(loadings_now, loadings_prev)
for i in range(k):
dot_val = float(np.dot(aligned[i], loadings_prev[i]))
if dot_val <= 0:
raise AssertionError("Aligned component has non-positive similarity")
if not np.isclose(abs(dot_val), 1.0, atol=1e-10):
raise AssertionError("Aligned component similarity not close to 1")
loadings_now = loadings_prev.copy()
loadings_now[1] *= -1
aligned, _, _, _ = _match_and_orient_impl(loadings_now, loadings_prev)
dots = np.einsum("ij,ij->i", aligned, loadings_prev)
if not np.all(dots > 0):
raise AssertionError("Sign flips were not corrected")
if __name__ == "__main__" and os.environ.get("RV_SELF_TEST") == "1":
_self_test_match_and_orient_impl()
raise SystemExit(0)
def match_and_orient_loadings(
loadings_now: np.ndarray, loadings_prev: np.ndarray | None
) -> np.ndarray:
aligned, _, _, _ = _match_and_orient_impl(loadings_now, loadings_prev)
return aligned
def match_and_orient_diagnostics(
loadings_now: np.ndarray, loadings_prev: np.ndarray | None
) -> tuple[str, list[bool], list[float]]:
_, perm_used, flip_flags, sims = _match_and_orient_impl(loadings_now, loadings_prev)
return perm_used, flip_flags, sims